-
Kotlin Coroutine (코루틴) 내부 동작원리안드로이드 2024. 3. 26. 22:55
일이 바쁘다는 핑계로 계속해서 블로그를 미루고 있었는데, 최근 관심있게 공부중인 내용이 있어 이에 관해 정리해보고자 글을 작성하게 되었다.
안드로이드 앱을 개발하며 서버와 API 를 이용한 네트워크 통신 등의 비동기 처리가 필요한 기능을 구현할 수 있는 방식은 여러가지가 있다. AsyncTask, RxJava, Coroutine 등등..
그 중 Coroutine 은 내가 알고 있는 기존의 처리 방식과 매우 달랐다. suspend 함수를 통해 Main thread 에 대한 간섭 없이 서버로부터 데이터를 받기까지 기다릴 수 있었는데, 이게 어떻게 가능한 것인지 내부 구현 방식이 궁금해졌고, 이에 대해 공부해보았다.
Concurrency 와 Parallelism
Coroutine 의 완벽한 이해를 위해선 Concurrency (동시성) 와 Parallelism (병렬성) 에 대한 개념이 필요하다.
아래와 같이 5분이 걸리는 작업과, 7분이 걸리는 작업 2가지가 있다고 생각해보자.

이 때, Concurrency 방식으로 2가지 작업을 수행한다면 아래와 같이 수행된다.

Concurrency 방식의 작업수행 2개의 작업이 아주 짧은 시간씩 번갈아가며 수행되고, 사용자는 이 2가지 작업이 동시에 수행되는 것과 같이 느낄 수 있다.
Concurrency 방식은 Parallelism 방식에 비해 자원을 적게 소모한다는 장점이 있지만, 보다시피 2가지 작업이 실질적으로 동시에 수행되지 않아 2개 작업 시간을 합친 12분이 소요된다. (실제 계산상으로는 Context Switching 비용이 있어 12분보다 조금 더 소요될 수 있다)
이와 다르게 Parallelism 방식은 아래와 같이 수행된다.

Parallelism 방식의 작업수행 실제로 2가지 작업이 병렬적으로 진행되어, 총 작업 시간은 2가지 작업 중 가장 많은 시간이 걸리는 7분만에 끝낼 수 있다. 소요되는 시간은 적지만, 2가지 작업을 동시에 수행하기 위해서는 Concurrency 방식보다 자원이 더 많이 요구될 수 있다.
Coroutine 은 위 2가지 방법 중 Concurrency 방식을 더욱 효율적으로 사용하기 위한 기술로, Context Switching 시간을 최소한으로 줄여 작업을 전환할 수 있게 한다. Coroutine 이 Context Switching 시간을 줄이는 방법은 다음과 같다.
JVM 메모리 구조
Coroutine 이 Context Switching 을 효율적으로 만든 방법을 이해하려면 JVM 의 메모리 구조에 대해서도 이해하고 넘어가야 한다. JVM 메모리는 아래 그림과 같은 구조로 이루어져 있다.
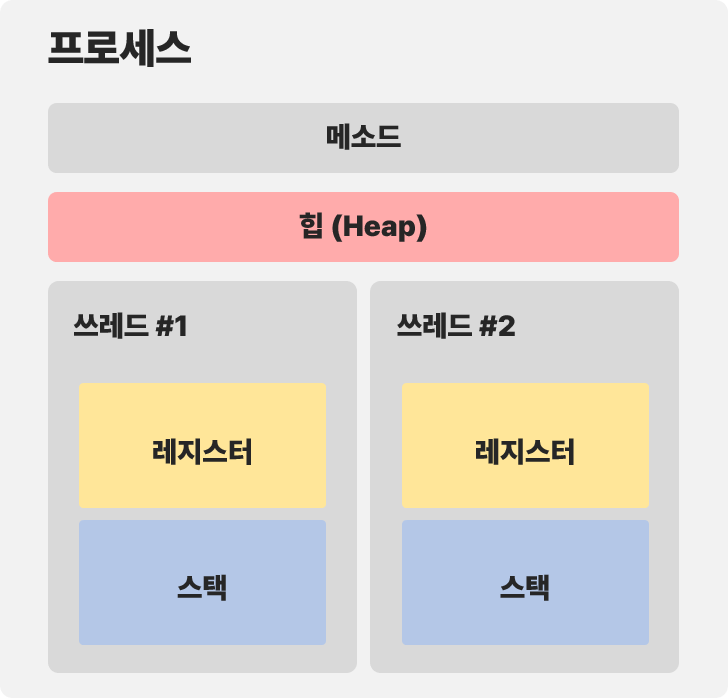
간략화한 그림이다 프로세스가 실행되면, 내부 데이터 저장을 위해 메소드와 힙 영역을 JVM 으로부터 제공받는다. 또한 해당 프로세스에서 작업 처리를 위해 쓰레드를 생성하면 각 쓰레드별로 스택 영역을 제공받게 된다. 여기서 메소드와 힙 영역은 모든 쓰레드가 공유하며, Coroutine 은 이 점을 이용한다.
이 지점에서 앞에서 본 Concurrency 방식에 대해 다시 알아보자. Concurrency 방식은 여러개의 쓰레드를 조금씩 나눠 실행하기 때문에, CPU 가 연산 시에 사용하던 쓰레드 #1의 메모리 주소에서, 쓰레드 #2의 메모리 주소로 옮겨가는 Context Switching 과정이 필요하다. 또한 쓰레드가 2개일때는 큰 문제가 되지 않을 수 있지만 쓰레드가 100개, 1000개가 된다면 각 쓰레드별로 할당되는 스택 영역도 1000개가 되어 이 또한 프로그램 성능에 영향을 끼칠 수 있다.
그래서 Coroutine
Coroutine 은 작업의 연속된 처리를 위한 최소한의 정보 (continuation 객체라고 한다) 만을 모든 쓰레드가 공유할 수 있는 힙 영역에 저장하고, 하나의 쓰레드에서 여러 비동기 작업을 처리할 수 있게 한다.
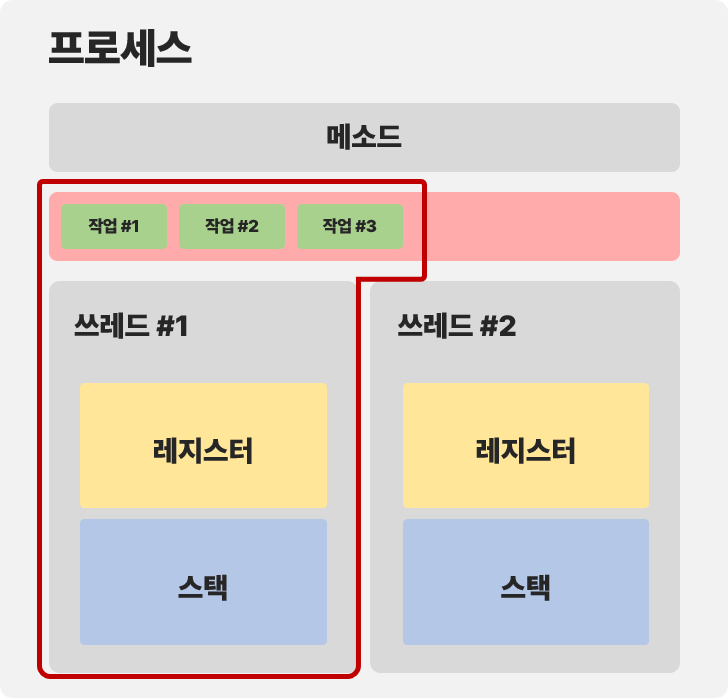
이런 느낌이랄까 각 작업별 진도상황을 continuation 이라는 객체에 담고, 이를 힙에 저장한다. 쓰레드는 작업 수행 과정에서 저장된 continuation 객체를 불러와 작업을 이어나가며, 작업 내용을 continuation 객체에 저장하는 행위를 반복한다. 이를 통해 프로그램 Level 의 Context Switching 이 가능해지며, 여러 개의 작업을 수행하더라도 실질적으로는 하나의 쓰레드만 사용되므로 OS Level 의 Context Switching 이 불필요해진다. 이러한 특성으로 인해 Coroutine 을 Light Weight Thread 로도 부른다고 한다.
개념적인 부분은 어느정도 설명이 된 것 같은데, 조금 더 쉬운 이해를 위해 샘플 코드를 통해 Coroutine 의 내부 동작 구조를 알아보자.
코드로 알아보는 Coroutine
Coroutine 이 이용된 예시 코드를 하나 살펴보자
suspend fun updateUser(userInfo: UserInfo) { val token = requestToken() val updateResult = updateUserProcess(token, userInfo) }userInfo 라는 사용자 정보가 담긴 변수를 받아, 서버로부터 토큰을 받고, 토큰과 사용자 정보를 서버에 업데이트 시키는 코드이다.
suspend 함수는 네트워크나 DB 작업 등으로 인해 진행이 일시 중단될 수 있는 작업에 사용되는 함수로, 위 예시에서는 서버로부터 토큰을 받는 requestToken() 함수와, 받아온 토큰을 이용해 서버의 user 정보를 업데이트시키는 updateUserProcess() 함수가 suspend 함수로 가정한다. 또한, suspend 함수는 suspend 함수 내부에서만 호출이 가능해 이 2가지 함수를 모두 호출하고 있는 updateUser() 함수도 suspend 함수로 선언되어 있다.
기본적으로 Coroutine 은 Kotlin 기반이고, Kotlin 은 JVM 위에서 실행되므로 이 코드 또한 실행 시 JVM 에 의해 바이트코드로 변환된다. 이 때 위 코드는 아래와 같이 변경된다.
fun updateUser(userInfo: UserInfo, cont: Continuation) { val myContinuation = cont as? MyContinuation ?: object : MyContinuation { fun resume(…) { updateUser(null, this) } } switch (myContinuation.label) { case 0: myContinuation.userInfo = userInfo myContinuation.label = 1 requestToken(myContinuation) case 1: updateUserProcess(token, userInfo, myContinuation) … } }바이트코드와 완벽히 동일하진 않지만, Coroutine 에서 작업 내용을 저장하고 다시 이어서 작업을 수행하는 방식 자체는 위 코드와 동일하다.
그럼 기존 코드와 변경된 부분을 살펴보자.
먼저, updateUser 의 함수 원형부터 달라졌다. 기존에는 없던 continuation 파라미터가 추가되었는데, suspend 함수들은 이런식으로 맨 마지막 파라미터로 continuation 객체를 전달받도록 변형된다.
다음으로, continuation 객체를 생성하고 초기화하는 작업이 추가되었다. 쉽게 풀어보자면, suspend 함수들은 각각 자신만의 continuation 객체를 가지고 있는데, 인자로 전달받은 continuation 객체가 자신의 것이 맞는지(이미 이전에 초기화되어 받은 것인지) 확인하고, 그렇지 않다면(최초 초기화 과정이라는 뜻) 나만의 continuation 객체로 캡슐화 하는 과정을 거친다.
그리고 continuation 객체 내부에는 resume() 함수가 구현되어 있는데, 해당 함수는 자기 자신을 다시 호출하는 재귀 함수로 이루어져 있다. 이렇게 구현되어 있는 이유는 조금 더 코드를 살펴보면 알 수 있다.
마지막으로 switch case 문이 구현되어 있다. 이 부분이 실질적으로 Coroutine 에서 한 쓰레드를 가지고 여러 작업을 수행하는 원리라고 볼 수 있을 것 같다. switch 에서는 continuation 객체의 label 값을 체크해 작업 진행상황을 체크하는데, 이 label 값은 최초 0으로 초기화되어 있으며, JVM 내부적으로 하나의 suspend 함수당 하나의 label 값이 자동으로 mapping 된다.
case 0 부분을 자세히 분석해보자. 먼저 인자로 전달받았던 userInfo 값을 continuation 객체의 멤버변수로 저장해둔다. (계속 쓰일거니까) 그리고 suspend 함수(requestToken()) 실행 전, label 값을 다음 작업 순서인 1로 변환시킨 뒤 requestToken() 함수를 실행시킨다.
requestToken() 함수 또한 원형에서는 인자가 하나도 없었으나, suspend 함수로 가정했으므로 continuation 객체를 인자로 전달받게 되는데, 이 때 기존에 초기화 해 두었던 continuation 객체를 인자로 전달받는다. 이후 requestToken() 함수의 작업이 완료되면 내부적으로 전달받은 continuation.resume() 함수를 호출하게 되는데, 이 때 continuation.resume() 에서는 자기 자신(updateUser()) 을 호출하도록 구현되어 있으므로 continuation 객체의 label 값이 1 이 된 상태로 updateUser() 함수가 호출된다.
이로 인해 switch case 문에서 label 이 1 인 상황에서의 다음 suspend 작업 (updateUserProcess()) 을 수행할 수 있게 되며, 이같은 동작이 반복되는 구조이다.
이렇게 Coroutine 내부 동작 구조 분석이 완료되었다. 결과적으로 Coroutine 을 가장 효율적으로 사용하기 위해선 최소한의 쓰레드만 사용해 개발하는것이 중요하다고도 볼 수 있을 것이다.
'안드로이드' 카테고리의 다른 글
[Kotlin] Loom 에 대해 (Room 아님) (3) 2023.04.16 Object 와 Companion Object 의 차이점에 대해 (0) 2023.04.09 sealed class 란? (0) 2023.04.02 [Jetpack Compose] 스낵바 표시, MutableState 사용기법에 대해 (0) 2023.03.18 Firebase Crashlytics 에 대해 (0) 2023.03.05 댓글